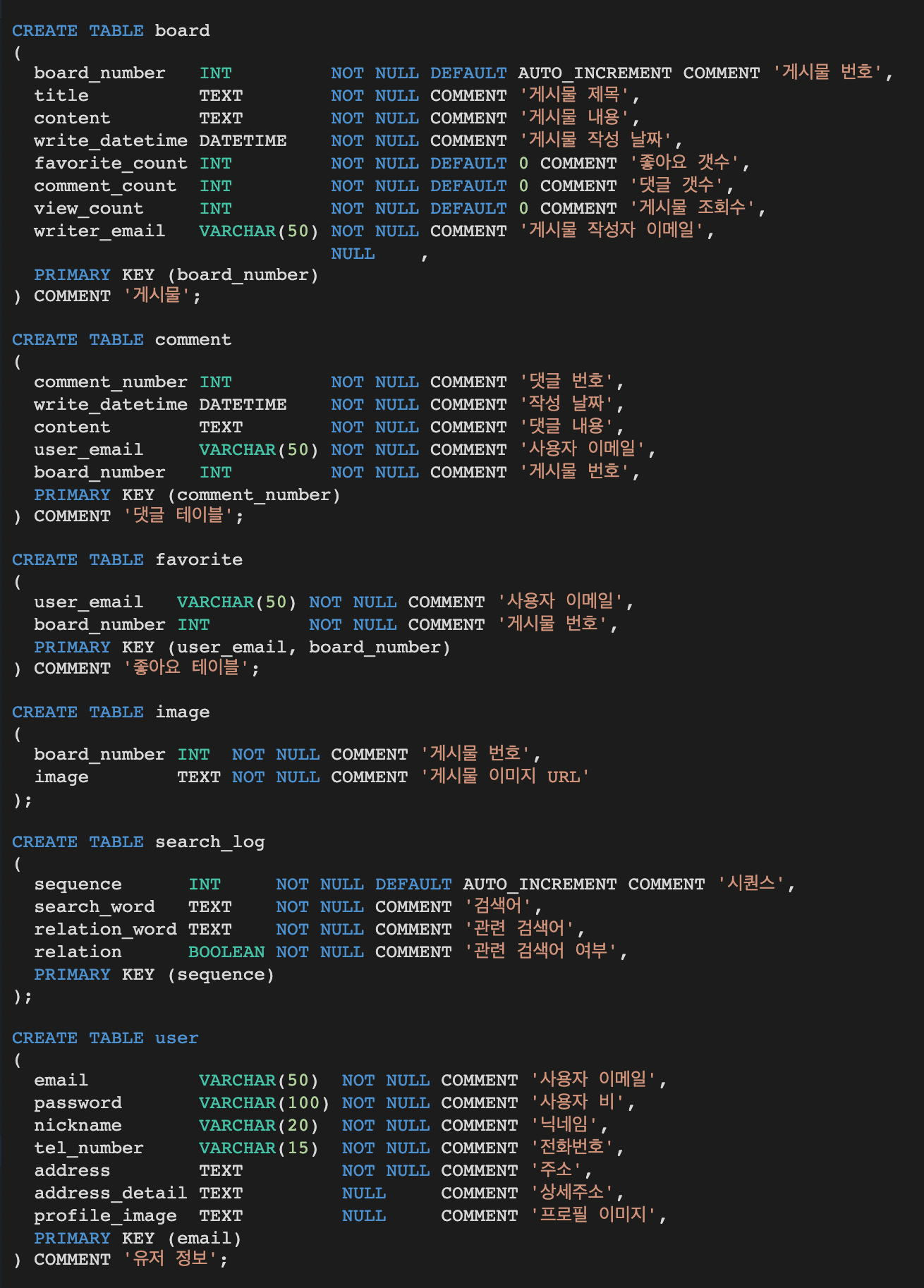
SELECT
데이터 조회의 기본이 되는 select
SELECT name, age FROM users;users 테이블에서 name과 age 칼럼을 선택하여 조회
DISTINCT
SELECT DISTINCT country FROM customers;
정렬 및 제한
ORDER BY
SELECT name, age FROM users ORDER BY age DESC;users 테이블의 사용자들을 나이가 많은 순으로 정렬
LIMIT
SELECT name FROM users ORDER BY signup_date DESC LIMIT 5;최근에 가입한 5명의 사용자 이름을 조회
데이터 형식과 함수
Date_format
SELECT DATE_FORMAT(birthday, '%Y-%m-%d') AS formatted_date FROM users;users 테이블의 birthday를 YYYY-MM-DD 형식으로 변환하여 조회
Format
숫자를 포맷팅하여 문자열로 반환. 예를 들어 소수점 아래 숫자를 제한하거나 천 단위 구분자를 추가할 수 있다.
SELECT FORMAT(total_price, 2) AS formatted_price
FROM sales;sales 테이블의 total_price 칼럼을 소수점 둘째 자리까지 포맷팅 하고 천 단위 구분자를 추가하여 반환
Year
SELECT YEAR(birthday) AS birth_year
FROM users;users 테이블의 birthday 칼럼에서 년도를 추출
CTE(Common Table Expressions)
WITH
with는 서브 쿼리를 지원한다. cte를 정의할 수 있다.
WITH customer_totals AS (
SELECT customer_id, SUM(amount) AS total_spent
FROM orders
GROUP BY customer_id
)
SELECT *
FROM customer_totals
WHERE total_spent > 1000;with를 통한 서브 테이블 예시. 각 고객의 총 지출 금액을 계산하고, 1000이상 지출한 고객을 찾는다.
WITH RECURSIVE number_sequence AS (
SELECT 0 AS number
UNION ALL
SELECT number + 1 FROM number_sequence WHERE number < 24
)
SELECT * FROM number_sequence;이렇게 재귀를 통해 0부터 24까지의 숫자를 생성할 수도 있다.
Group by, Having
GROUP BY는 데이터를 그룹화 한다.
그룹에 조건을 적용할 때는 HAVING을 사용한다
SELECT category, COUNT(*) AS total_products, AVG(price) AS average_price
FROM products
GROUP BY category
HAVING COUNT(*) > 10 AND AVG(price) > 500;카테고리 별로 제품 수와 평균 가격을 계산한다. 제품 수가 10개를 초과하고, 평균 가격이 400을 넘는 카테고리만 결과로 나타낸다.
JOIN + ON
on의 조건을 기준으로 테이블을 결합한다. 그냥 join이라면 on 조건 기준으로 공통된 조건이 없는 행을 버리게 된다.
using(column)으로 사용할 수도 있다.
leftjoin, rightjoin으로 사용될 수 있는데, 각각 좌측과 우측을 기준으로 공통된 조건이 없는 행도 남겨둔다.
SELECT orders.order_id, customers.name
FROM orders
JOIN customers ON orders.customer_id = customers.customer_id;주문 테이블과 고객 테이블을 customer_id로 조인하여 주문 id와 고객 이름을 조회한다.
UNION, UNION ALL
쿼리 결과를 단순히 합친다. 결과가 단순히 행으로 추가되는 테이블이라고 이해할 수 있다.
때문에 쿼리의 결과 칼럼 수가 같아야 한다.
SELECT name FROM products
UNION ALL
SELECT name FROM services;producs와 services 테이블에서 name을 조회하여 모든 결과를 합친다.
ORDERS 테이블
| customer_id | order_date | product_id | amount |
| 1 | 2024-03-10 | 101 | 200 |
| 2 | 2024-03-11 | 103 | 150 |
| 1 | 2024-03-15 | 102 | 300 |
produus 테이블
| product_id | category | price |
| 101 | Books | 200 |
| 102 | Electronics | 300 |
| 103 | Books | 150 |
WITH recent_orders AS (
SELECT customer_id, MAX(order_date) AS last_order_date
FROM orders
GROUP BY customer_id
)
SELECT o.customer_id, o.last_order_date, p.category, SUM(p.price) AS total_spent
FROM recent_orders o
JOIN orders od ON o.customer_id = od.customer_id AND o.last_order_date = od.order_date
JOIN products p ON od.product_id = p.product_id
GROUP BY o.customer_id, p.category
HAVING SUM(p.price) > 500;각 고객의 최근 주문 날짜를 찾고, 해당 주문에서 특정 카테고리의 제품에 500이상 지출한 고객을 식별한다.
쿼리 실행 결과
| customer_id | last_order_date | category | total_spent |
| 1 | 2024-03-15 | Electronics | 300 |
최근 주문에서 Electronics 카테고리에 300의 금액을 지출했다는 것을 보여준다. 고객 2의 최근 주문은 총 지출액이 500보다 낮은 150이기 때문에 HAVING절에 의해 결과에서 제외된다.
'데이터베이스' 카테고리의 다른 글
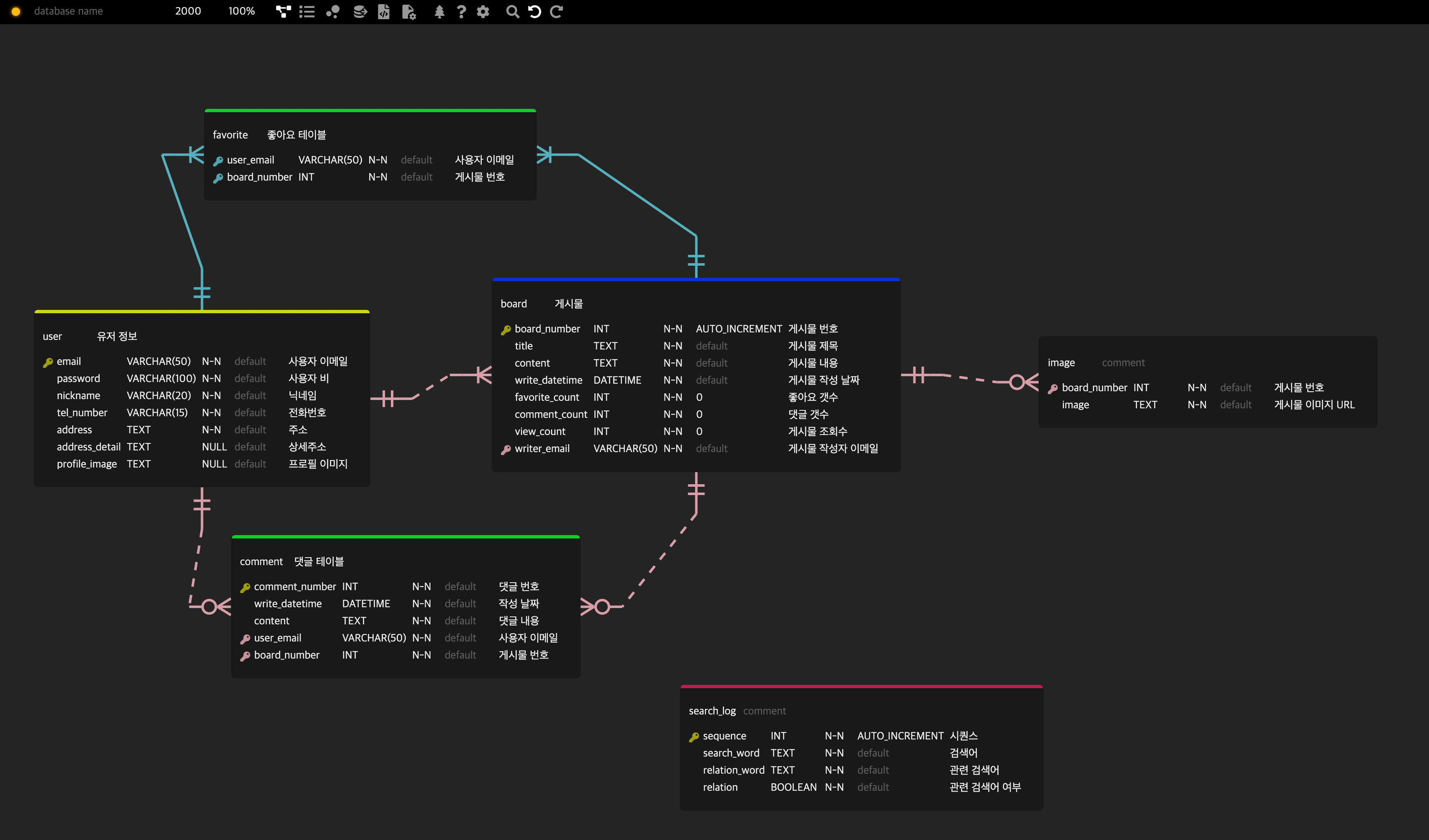
| [블로그 프로젝트] ERD EDITOR (0) | 2024.01.11 |
|---|